Playing Atari Games with AI
I used Deep Q Networks to create an algorithm that can play atari games like pong and breakout.
DQNs are a combination of reinforcement learning and deep neural networks. They use neural networks to approximate Q values which is then used by the reinforcement algorthim to take action depending on the epsilon greedy strategy and maximium reward given for each action.
View More in-depth explanation here.
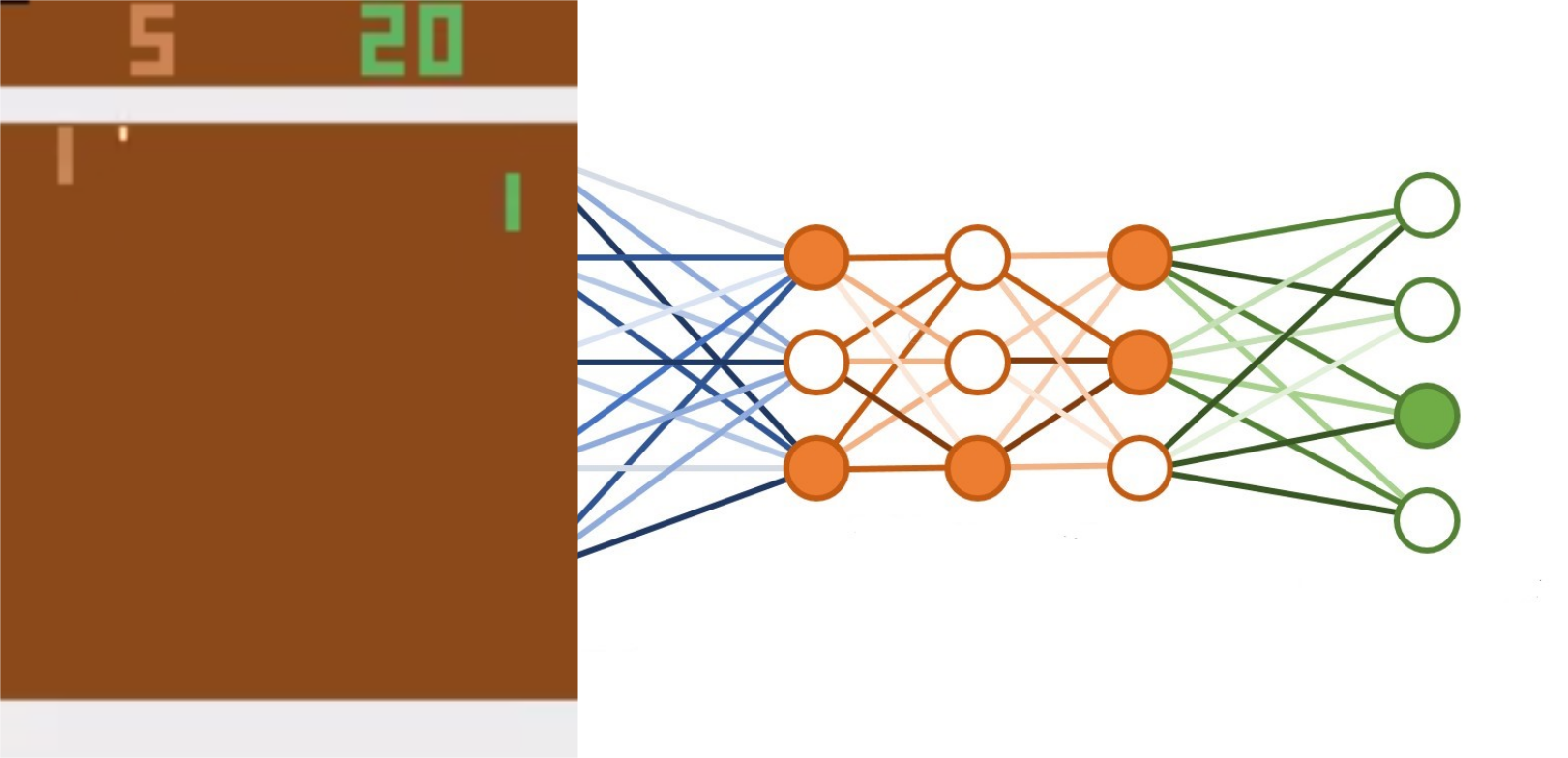
Q-table Vs Deep Q learning
Reinforcement learning and Q-Tables
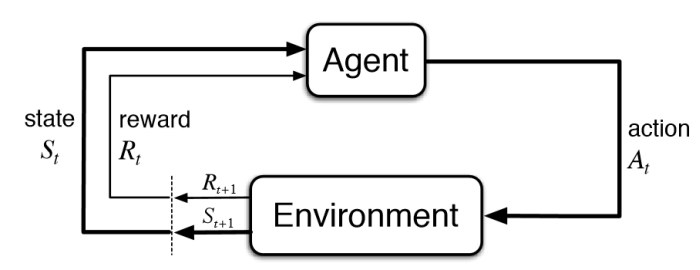
Reinforcement learning is a type of AI that uses a reward and punishment system
where the goal is to maximize the reward received. There are 4 main components
to this type of learning: The agent, environment, action, and reward.
The agent in RL is the component that makes the decision of what action to take. The actions are all the
possible things the agent can do. For example, run, jump, walk, do nothing.
The environment is typically a set of states, and the reward is what will motivate our agent to take good actions.
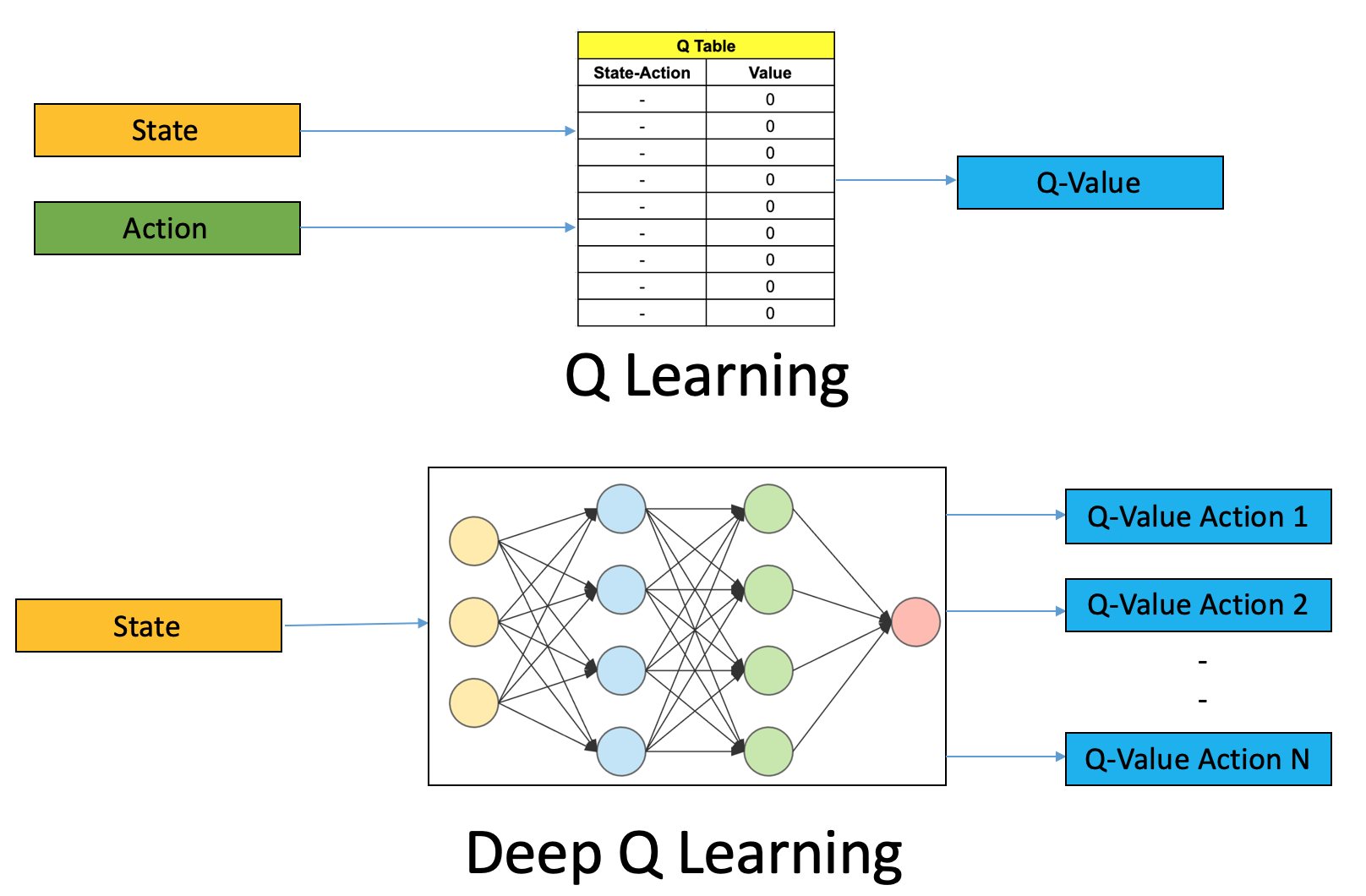
Q-Learning
Q learning is a way for the agent to decide what action to take. At first,
the agent has no idea what to do. This is where we use Q-Tables, in order to find the "quality" of each action.
However, for Atari games we can't calculate the quality of each movement since there are way too many. Thus,
we use a neural networks to approximate the Q-values which the agent will base its actions off.
This in practice will have take a smaller toll on our network and reduce required computational power.
You can also read DeepMind's research paper
here.
Conclusion
Deep reinforcement learning is surrounded by mountains and mountains of hype. And
for good reasons! Reinforcement learning is an incredibly general paradigm, and in principle,
a robust and performant RL system should be great at everything. Merging this paradigm with the
empirical power of deep learning is an obvious fit. Deep RL is one of the closest things that looks
anything like AGI, and that's the kind of dream that fuels billions of dollars of funding.
Unfortunately, it doesn't really work too well yet.
Now, I believe it can work. If I
didn't believe in reinforcement learning, I wouldn't be working on it. But there many
problems we still need to tackle. Mabye you can solve some of them one day!
